
Chapter 7
Questioning
The Ideology Of Testing:
The modernist search for an appropriate mental yardstick
(1964-1981)
Paul F. Ballantyne
This chapter covers a period in which the formerly unquestioned megalith of college entrance exams, vocational tests, and public school standardized testing was first brought into open debate. The long-standing subdisciplinary claims had been that standardized psychometric tests: (1) open up educational opportunity; (2) level the playing field for job applicants; and (3) help young people select the societally useful occupations to which they are best suited. Given the widespread application of psychometrics during the Cold War era, concerns over the expanding role of testing in American society and over their historically biogenic assumptions were bound to produce subdisciplinary adjustments designed to make testing more acceptable to the new Great Society era marketplace.
Already by 1964, for instance, liberal-minded social scientists such as Leona Tyler (who sympathized with president Johnson's Great Society program) recognized that the traditional trait approach to individual differences had not turned out to be the "open-sesame" to scientific vocational guidance (p. 75). She suggested that a comprehensive science of individual differences would have to be far broader and the content of her succeeding works reflected that view (1965, 1969, 1974, 1978, 1979). Similarly, works by Lee Cronbach (Cronbach,1960, 1969, 1970, 1977; Cronbach & Gleser ,1965), which attained distinction as standard references for training in the testing tradition, now advocated the joint application of experimental (Fisherian), correlational (Galtonian), and especially longitudinal (ontogenetic) methods in an effort to obtain a more balanced approach to the nature-nurture debate and its implications for education, business, and mental assessment.
But even having made these somewhat rhetorical "interactionist" adjustments to its former (fundamentally quantitative-administrative) concerns, the testing subdiscipline was eventually attacked from all sides by those who questioned the underlying ideology and motives of testing itself. During the mid-1960s and late-1970s, both the traditional claims and the successive disciplinary adjustments of the testing industry were brought under public (and judicial) scrutiny.
Chapter overview:
To
understand why the reanalysis of testing dogma (and its administrative infrastructure)
occurred during the mid-1960s to late-1970s period, an overview of the era's progressive
federal social reforms (including the Economic Opportunity Act, and the Civil
Rights Bill of 1964); and of ongoing foreign policy concerns (including the domestic
fallout of the Vietnam conflict) is provided in section one. The structure
of the
A crucial part of section two is the exposure of the ideological and methodological weaknesses of the traditional interactionist (genes plus environment) understanding of human intellect, particularly with regard to the pervasive "rectangular capacity" metaphor of human intellect. The brief era of so-called naive environmentalism, which is said to have provided an initial disciplinary rationale for the ameliorative Project Head Start (in 1965) and for its initial assessment (up to 1971) is then outlined. Importantly though, section two also shows that the basic assumptions (circa 1965) and subsequent assessments of Head Start utilized a broader motivational criterion of success which avoided falling into the former "IQ Trap" of empirical assessment. This utilization of broader criteria was the first bold (though under-recognized) step beyond the interactionist platform of human intellectual assessment.
Ironically, the methodological weakness of the well-meaning interactionist approach (including those appealing to expectancy effects in testing or to the cultural bias of standardized tests) actually predisposed the subdiscipline toward a modern resurgence of Social Darwinism. The biogenic claims of Arthur Jensen (1969) revealed to the public just how vulnerable the administrative structure of traditional general psychology was to essentially unconstitutional biogenic arguments. The largely face-saving reactions of professional organizations (such as the APA and SPSSI) to the Jensen affair are used in section two as evidence that general psychology possessed few new insights to address the growing public concern over implications of ongoing race differences in test performance.
It then highlights, how a fundamentally important theoretical distinction between "inheritance" and "heritability" of IQ scores was adopted explicitly by testing outsider James Lawler in 1978. That distinction (initially made by others), however, was just one part of Lawler's wider socio-historical argument against existing biogenic (and interactionist) positions; an argument that provided a somewhat sounder (transformative) methodological platform for assessment of test results. Ironically though, this potentially useful second step beyond the interactionist testing platform was actively ignored by both APA psychologists and by the firmly entrenched infrastructure of ETS higher educational testing regimes.
During the wider context of Watergate era of calls for public accountability in politics, litigation in all areas of testing was forthcoming and test providers (such as the ETS) were eventually forced to respond. Section three, therefore, begins with an account of important (school and vocational) test litigation decisions (up to 1980), and then details the ensuing ETS evasions regarding its corporate structure, its goals, the validity of its tests, and its own culpability in maintaining a highly undemocratic socio-economically stratified society.
In this section the domestic policy initiatives of Johnson's Great Society program and the growing credibility gap regarding executive presidential power during the succeeding Nixon era are described as a means of understanding the wider cultural background for the rise of more disciplinary concerns over ability testing issues (highlighted in sections two and three). In the 1964-1974 decade, issues of public accountability and consultation came to the fore in every aspect of American life. This accountably movement was initially began around the issue of Civil Rights but was also increasingly evident in the State and local issues surrounding the impact of ongoing highway (and so-called Urban Renewal) programs on urban neighborhoods (see Jacobs, 1961; Piven & Cloward, 1979). In both these areas of domestic concern, considerable political weight was then afforded to calls for accountability by way of federally enacted Great Society legislation (designed to enshrine the right to equality of educational and vocational opportunity).
Similarly,
in terms of foreign policy issues, the main concern of the era was the growing
American entanglement in
Kennedy's Mandate and Johnson's Great Society
The Soviet-American showdown over Cuba and the signing of the Kennedy-Khrushchev Limited Testing Ban Treaty led to a period of relatively relaxed tension in the Cold War and 1963 was the first year in which domestic events took priority in the minds of Americans. Despite the early Cold War era promises of peace and justice for all, racial and economic inequality remained part of the emerging American physical and economic landscape. The Internal Improvement Act (1956), which was designed to link every major American city with highways (built to standard specifications) and the business biased so-called Urban Renewal programs (carried out by State and city administrations) had locked the nation into an ironic (and largely undemocratic) demographic dichotomy. A de facto geographical Apartite had been set up where low income communities (made up primarily of persons of color) were now confined to the old city cores while the more affluent (primarily White) communities moved out to the suburbs (Clark, 1965; Herman, Sadofsky, & Rosenberg, 1968).
Increased
participation on the part of northern Blacks in support of Civil Rights was the
inevitable result of the emerging inequalities and the issue both drew national
attention and reached riot proportions as southern states tried to quell these
demonstrations with force (Muse, 1968; Graham, 1990). A
large part of Kennedy's appeal to voters in the 1960 election had been that he
openly acknowledged that in America, no man was enslaved but many were not yet
free, and, further, that part of the reason for this was the existence of discriminatory
state and federal policies (Graham; 1992). As the campaign for Civil Rights
of Negro Americans reached national proportions in 1963, the president was forced
to utilize federal marshals and troops to enforce integration at the
After Kennedy's assassination (at the end of that year) vice-president Lyndon B. Johnson assumed office and worked to complete Kennedy's mandate for civil rights, education, and antipoverty initiatives especially with respect to the Civil Rights Bill of 1964. Elected in 1964 by a landslide of popular support, Johnson then worked to establish bipartisan support for his own Great Society program in a way which harped back to similar Democratic programs of the Great Depression (Kaplan & Cuciti,1986). Here, Johnson utilized his considerable prowess in machine politics to advance the cause of federally funded domestic programs (which took effect from the mid-1960s onward). This "War on Poverty" was intended to provide help for those who were trapped in poverty by sociological circumstances (Harrington, 1962; Moynihan,1965; Levitan, 1969; Levitan, & Cleary, 1973). It was from within the context of Great Society era legislation that the dictatorial urban renewal programs of the early 1960s and the similar brick and mortar era of schools (where State engineers, and city school administrators had called the shots), was successively confronted by multi-ethnic community action groups (Frieden, 1965; Alinsky, 1971).
Dynamics of Great Society initiatives
The goal of the Great Society program was to eliminate the paradox of poverty in the midst of plenty by opening up opportunities for education and job training for youths and for minority Americans. Three federal initiatives are important in this respect: The Vocational Education Act (1963); Economic Opportunity Act (1964), and the Civil Right Bill (1964). The first initiative was scuttled in the Senate but the mere demographic fact of the coming of age of the baby boom generation in the mid-1960s necessitated that the U.S. Employment Service (with financial support from the Office of Economic Opportunity) establish special offices for youths (especially those located on the peripheries of ghetto areas).
Under
Title I (Part A) of the Economic Opportunity Act (1964), Job Corps training, education,
and work experience programs were brought into effect. Under Part B of the
Act, Neighborhood Youth Corps and on-the-job training programs were established
in public agencies. Part C of the Act, established a funding plan for federal
support to needy colleges and university students from low-income families (
Entanglement in
Prior to 1963, Johnson had been weary of U.S. involvement in Vietnam but was now passed the legacy of support for South Vietnam. Unlike his Republican adversary for the 1964 election, Johnson did not believe that American objectives (at home or in Vietnam) would be achieved by all-out bombing or invasion of the North (Johnson, 1971). Instead, the restrained Kennedy era path of limited engagement and technical advisor support of the south was initially adopted (Herring, 1994). The domestic priority, for Johnson, was political reform through his Great Society program and an all-out war in Vietnam might prove considerably damaging to that program. On the other hand, if the U.S. now abandon Vietnam to communism, this would also be politically damaging. Johnson's solution, between 1964-1965, was to attempt to limit the impact of the war on the American public by secretly escalating military involvement while providing overly optimistic military reports to Congress in order to maintain bipartisan support (Barrett, 1997).
In early 1964, increased logistical support was provided to the South Vietnamese Army and Navy but U.S. support for the Diem era Strategic Hamlet pacification programs (in the Mekong Delta and Central Highland regions) were scaled back and then formally withdrawn (Kolko, 1985; Metzner, 1995). The ideological battle to win the hearts and minds of Vietnamese villagers had been lost (Hunt, 1995) and and the U.S. was now moving into an era of increased military involvement in an undeclared war. [157] At the same time, Johnson was determined to move slowly in this escalation and on April, 7, 1965, he publicly offered economic aid to the North in exchange for peace. This diplomatic overture, like many other successive ones, however, was rejected by the North Vietnamese leadership (Hammond, 1992).
Entanglement
Sporadic escalation of American forces in Vietnam and the expansion of an unpopular military draft followed Johnson's 1965 peace overtures. The rate of military induction went from 8,700/month (average over January 1962-June 1965) to 29,000/month by the fall of 1965 (Baskir, & Strauss,1978). Initially, American Marine and Army ground forces were ordered to establish air fields, and communications facilities, but to also restrict their area operations to defensive objectives -maintaining area control via limited tactical search and destroy operations (Stanton, 1985). The major U.S. offensive strategy was to be the bombing campaign (Operation Rolling Thunder) but the surprising scale of NLF offensives in May, 1965, indicated the need for more American troop deployments to Vietnam.
The U.S. Commander in Vietnam, Marine General C. Westmoreland now argued for extending the ground campaign into Laos, Cambodia, and into North Vietnam but Johnson feared this would draw China or even the Soviets into the war (Herring, 1996). Throughout his presidency, therefore, Johnson restricted the bombing campaign to presidentially approved targets and categorically ruled out any ground invasion of the North.
The political limitations on American combat in Vietnam meant that the military leadership had to fight battles on three limited fronts. There were powerful North Vietnamese Army units on the DMZ (separating North and South); there were NLF concentrations hidden in the forested Central Highlands; and NVA regiments based in Cambodia opposite Saigon to the south. Throughout the war, Communist forces could present a military challenge in any of these three regions and force the Americans to respond. Those forces could also break off attacks at any time by retreating into an extensive system of tunnel complexes or by slipping back across the adjacent borders where American forces were forbidden to follow.
As
the American ground force levels rose, so did the casualties. Throughout
1966, U.S. public opinion against the war, and against the troop escalations in
particular, were played down by the Johnson administration which promised that
the communists in Vietnam could not possibly sustain their war effort for too
much longer. [158]
The
The process of deciding which men were actually drafted was controversial from the earliest days of the Vietnam war. Up to December, 1969 the draft operated under procedures similar to those used in World War II and the Korean war. Under the Selective Service Act (1948; 1967) men who reached the age of 18 were required to register and report to their local draft board for classification. The sequence of induction from among those available for service was set by order of the president, with the highest priority for delinquents, second priority for volunteers, and third priority for non-volunteers between the ages of 19 and 25, in order of their dates of birth (i.e., from oldest to youngest). In the spring of 1968, the rate of induction peaked at 42,000/month, with widespread student protests against the draft (Heineman, 1994). [159]
The
draft process was substantially changed by the introduction of the draft lottery
in late 1969. A key feature of the lottery was that each cohort was at risk
of induction for only a single year, rather than for the entire period between
the ages of 19 and 25. The first lottery, held
Induction tests (AFQT, ASVAB)
The main military classification test used by the Selective Service System during the Vietnam conflict was the Armed Forces Qualification Test (AFQT), initially developed in 1950 (see fig. 51).
Figure 51 Vietnam testing of inductees. Once inductees had been drafted by way of lottery system, they were given the Armed Forces Qualification Test (AFQT) plus various vocational proficiency tests which varied from service to service (Photo from Lindgren, et. al., 1966). In 1968, the Armed Forces began moving toward a uniform inductee exam called the Armed Services Vocational Aptitude Battery, (ASVAB) which included not only academic tests but also more vocational measures (Auto & Shop Information, Mechanical Comprehension, Electronics Information).
This screening test consisted of 100 multiple-choice questions in the following subjects: vocabulary, arithmetic, spatial relations, and mechanical ability. Each service set their own AFQT composite score cut-offs and score pattern preferences. Unlike the W.W.II era Army General Classification Test speed was not emphasized in the AFQT and instructions for test procedures were also made more explicit. Like the older AGCT, however, the AFQT was used to assign inductees into five different mental "grades" (ranging from I to V). Of the five grades, the grade level V was excluded from opportunity to serve. From the military point of view, therefore, AFQT test scores, like those of W.W.I and W.W.II era "general" induction tests, were interpreted as a rough measurement of trainability.
Similarly,
the de facto service allocations of draftees was largely determined by
political contingency and military requirements (rather than on psychometrics
grounds). Men who were drafted were nearly all assigned to the Army.
Although inductees stood only a 38 percent chance of actually serving in
A subsequently developed test, the Armed Services Vocational Aptitude Battery, (ASVAB), began in 1968 as a joint military effort to modernize standardized military induction testing. It consisted of ten short individual tests covering Word Knowledge, Paragraph Comprehension, Arithmetic Reasoning, Mathematics Knowledge, General Science, Auto & Shop Information, Mechanical Comprehension, Electronics Information, Numerical Operations and Coding Speed. The ASVAB takes approximately three hours to complete; two-and-a-quarter of which is test taking and the rest being instruction-giving time.
The ASVAB was used in high schools from 1968 onward, but it wasn't used for military induction purposes until a few years later. Notably, however, the ASVAB quickly replaced the GATB to become (and remain) one of the main military recruiting tools used in the nation's high schools. Under the Department of Defense Testing Program (commonly known now as the Career Exploration Program), students are given surveys about their interests, helped to identify personal characteristics, and use ASVAB scores to match their backgrounds to possible military and civilian careers. In addition, the Occupational Outlook Handbook, a career information resource produced by the US Department of Labor, provides detailed information on about 250 civilian and military occupations. [160]
In 1973 the ASVAB was used along side of the AFQT for induction purposes. That year, the draft was ended and the nation entered the contemporary period in which all military recruits are volunteers. Three years later, in 1976, the Armed Services Vocational Aptitude Battery (ASVAB) was introduced as the official mental testing battery used by all the services. At that point, the former Armed Forces Qualification Test as such was retired but an "AFQT score" was retained as a mere psychometric/statistical composite of scores derived from the math and verbal portions of the new ASVAB test. [161]
College and the Draft
Throughout most of the Vietnam war, men who were enrolled in college could obtain deferments that delayed their eligibility for conscription. These deferments were an effective though imperfect way to avoid military service. Those who finished a bachelors degree before reaching age 25 could also apply for a graduate deferment in the early years of the war (up to mid-1967) and could apply for occupational or dependent deferments throughout the period from 1965 to 1970. The rise in college entry rates of young men between 1964 and 1968 coincided with the rise in the number of men drafted into military service. Moreover, the drop in the number of indications between 1968 and 1973 was followed by a decline in college entry rates. "Draft avoidance" is said to have raised overall college attendance rates by 4-6 percent in the late 1960s, and raised the fraction of men with a college degree by up to 2 percentage (for men born in 1946-48).
The limited period of exposure, coupled with the relatively low rate of inductions after 1969, substantially reduced the incentives for enrolling or staying in college to avoid the draft (Angrist & Krueger, 1992). Only those with relatively low random sequence lottery numbers were at any risk of induction (men with higher lottery numbers had no need to pursue draft-avoidance strategies). In addition, men over age 20 were no longer at risk of the draft, and had no incentive to prolong their stay in college. Comparison of educational outcomes for men born in the early 1950s shows no significant differences between men with higher and lower lottery numbers, implying draft avoidance behavior was negligible even among those with the highest risks of conscription (Baskir & Strauss, 1978; Angrist & Krueger, 1992).
The Credibility Gap Exposed
The scale of the New Years 1968 "Tet" offensive, where NLF attacks were made on nearly all of the southern region provincial capitals and inside Saigon itself (including the government radio station, the presidential palace, and American Embassy), exposed a considerable "credibility gap" between what the American public had been told about the war and the realities of what they were now witnessing nightly on the television news networks (Braestrup, 1983; Hallin, 1986). If the communists were so close to defeat (as the military and president had claimed so often) how could they have launched an offensive on such a nationwide scale? In the aftermath of Tet, therefore, support for Johnson's handling of the war was at an all-time low.
Nixon's "Vietnamization" of the war
Johnson's
handling of the war cost him his popularity (Altschuler,
1990). In a televised speech on
Troop
reductions were forthcoming (and the rate of induction in fall 1969 was "reduced"
to 19,000/month), but when peace talks failed in 1969, Nixon authorized both stepped
up bombing in
In
the upcoming era of Watergate, the OPEC oil embargo, and the winding down of an
unpopular war, a full-scale crisis of confidence in American ideology was underway
(Matusow, 1984; 1998). Despite his reelection
in 1972 Nixon's leadership was made untenable by relentless press investigations
of the Watergate break-ins (Genovese,1999). Presidential impeachment proceedings
where eventually launched but were still underway when Nixon's Secretary of State
(Henry Kissenger) was able to broker a brief face-saving
ceasefire in
When
it was demonstrated that Nixon had both encouraged perjury and had conspired to
obstruct justice, he resigned on
Having
sketched out the historical context for ability testing in the
In section two, the shortcomings of the traditional interactionist approach to intelligence will be exemplified in: (1) the overlap between the "rectangular capacity" metaphor of human intellect with the former clearly biogenic literature; (2) the methodological inability of I.Q. scores to measure the ongoing success of the Head Start program (began in 1965) and; (3) the failure of general psychology (and its professional institutions) to counter-argue biogenic interpretations of ongoing race differences in standardized test performance. Rather, theoretical solutions to these shortcomings and concrete reforms of testing practices (in schools and in vocational selection) came from outside both the testing industry and the discipline of general psychology. As for the testing industry, in particular, its rise was linked with that of the military industrial complex. The emphasis in section three, therefore, will be on demonstrating: (1) that the test industry continued to function as a substantial barrier to the achievement of democratic ideals; and (2) what was done about it.
Weakness of Traditional Interactionism (1946-1979): Rectangular Metaphor, Head Start assessment, and Disciplinary adjustments
This section highlights the methodological weakness of the traditional interactionist (genes plus environment) understanding of human intellect, particularly with regard to the pervasive rectangular capacity metaphor of human intellect used by general psychology from 1946 onward. The brief era of naive environmentalism, which is said to have provided a disciplinary rationale for the ameliorative Project Head Start program (in 1965) and for its initial assessment (up to 1970) is also outlined.
It is then argued that the methodological weakness of that well-meaning variant of interactionism (and even of those appealing to the concepts of expectancy effects in testing or to the cultural bias of standardized tests) actually allowed a resurgence and continuation of the biogenic claims during the 1970s. In other words, instead of replacing (or renovating) the rickety methodological platform of interactionism, mainstream psychology (and the testing subdiscipline) went to great lengths to merely adjust (i.e., shore up) the already failing structure of this standard empirical research tradition.
Rectangular Capacity Metaphor
It is often claimed in psychological textbooks that so-called naive environmentalism of the early-1960s provided an initial disciplinary rationale for mid-1960s ameliorative Great Society programs such as Head Start (Hilgard, 1979; Atkinson, et a., 1990). This claim is only partially true. Its veracity lies in the fact that such situationism emphasized the so-called social origins of human intellect. Joseph Hunt's Intelligence and Experience (1961) for instance, provided a historical critique of past research into fixed intelligence, predetermined development, and inherited capacity. He suggested that subsequent research should be more interactionist. That is, it should concentrate on the "experiential side of the matter" (p.7), and further, that parental styles would likely be a fruitful area of research when attempting to understand the development of human intellect (see Weizmann, 1977 on these progressive aspects of Hunt's position and Scarr & McCartney, 1983 for a direct application of this approach).
Similarly, Benjamin Bloom's Stability and Change in Human Characteristics (1964), listed three social environmental "variables" important in child's intellectual development: (1) the overall amount of verbal stimulation; (2) the reward a child receives for verbal reasoning accomplishments; and (3) the amount of encouragement received for active engagement with problems of exploration of surroundings. A deprived intellectual environment during the early critical years (up to age 4), he argued, might produce IQ performance differences of 20 points or more (p. 89). Bloom, therefore, suggested that publicly funded ameliorative programs should be set up to ensure the intellectual well being of the nation's poor. This emphasis fell in nicely with the Great Society ideology of the Johnson era and is the most positive aspect of liberal interactionism.
What is not often mentioned in standard texts, however, is that both Hunt's and Bloom's inclusion of IQ scores as an appropriate empirical measurement of the success of ameliorative programs (and of intellectual growth itself) stood as a potentially damaging influence on the structure, scope, assessment, and ultimate longevity of succeeding ameliorative programs such as Head Start. Methodologically speaking, naive interactionists fell into what would later be called the IQ Trap of mental assessment. Their views were modern equivalents of the environmentalist pole of the traditional interactionist (genes plus environment) position which dates back to the early 1920s. Elaboration on this point is provided below but the emphasis here is that looking back just a few years (1946-1960s) explodes the myth of interactionism as a safe disciplinary platform for assessing the success of ameliorative programs.
Interactionism
itself, no matter how liberally interpreted, was a rickety methodological platform
for Great society era social reforms. Interactionism
has been defined as the view that "Heredity and environment always interact
and life is the maturation of an individual in an environment" (Engle, 1957,
p. 269). A clear exposition of interactionist
assumptions about human intellectual capacity is found in the diagrams in successive
versions of Psychology by
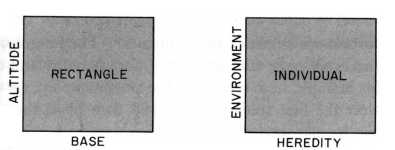
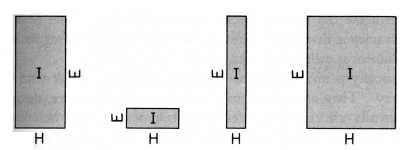
Figure 52 Rectangular Metaphor of intellectual capacity. "Although we cannot have a rectangle without both a base and an altitude, the base and the altitude can vary in length. An....individual may have a superior heredity and an inferior environment. Suppose there are two individuals with apporximately equally good heredity. One is place in a rich cultural environment, while the other is placed in a poor cultural environment. The resulting total individuals will be quite different. Or suppose two individuals with considerably different heredities are place in approximately the same environments. The total individuals developing will be quite different, owing to the factor of heredity" (from Engle, 1957). Woodworth & Marquis (1962) also held this view: "The individual [is] a product of heredity and environment. Increase the environmental stimulation (height of the rectangle) and you increase the area, but the hereditary factor (width) remains as important as ever" (p. 158).
While this common sense view of intellect with rectangles was (and is still) prevalent, it was also seriously flawed. One indication of these flaws (during the 1950s) was the clear bows to eugenics that view of intellect implied. This was certainly true in the case of Engle. [163] Hunt and others rejected the innatist bias of traditional interactionism and would, instead, stress the environmental plasticity of IQ scores. It should be noted, however, that in the rectangular metaphor itself, the H 'factor' is considered as apriori. That is, it is assumed that superior or inferior heredity is somehow there (i.e., provides a given apriori base) before the child is placed into the different environments (within which mental growth somehow takes place). This assumption was shared by both predeterminist and situationist interactionist accounts.
Bloom (1964), for instance, clearly spelled out his belief in a genetic component of human intellect: "As intelligence is now measured we believe that the equation MI=f(GP+E) is likely to account for the intelligence test scores at any age, where MI = measured intelligence, GP = genetic potential, and E = environment." (Bloom, 1964, pp.79-80). He did, attempt to mitigate the past "one-way assumption" (of the apriori status) of genes by suggesting (in a footnote) that it is "possible that the relation between GP and E is not a simple linear function but is a more complex interactive function." (p.80). Other 1960s environmental interactionists (such as J. Hunt) were far less forthcoming than Bloom with their underlying analogies but they still held on to the rectangular view of mental capacity (H+E). Their account, like all interactionist accounts of the nature-nurture debate, were modern extensions of the continuity view of mentality (e.g., Anastasi 1958, 1964, 1967a&b, 1968).
In both Hunt's and Bloom's liberal interactionist accounts, IQ measurements are implied to be an appropriate yardstick of mental growth. Thus, human intellect is still depicted as a quantitative continuity. This is an empirically descriptive method but is fundamentally flawed in that maturation (or continuous growth) does not capture the qualitative ontogenetic and socio-historical shifts of intellect which occur across the life course of human beings. The wider societal context of the becoming (or genesis) of human intellect is not sufficiently addressed by the actual empirical methods (especially use of IQ scores) being used by the naive interactionists. In other words, the realm of the social and societal are not merely a context for higher mental processes to be expressed in adult human activity. Rather, they are the sources for the very formation of higher mental processes from the sort of lower mental processes we share with animal and child mentality.
As indicated below, environmental interactionism lacked the methodology to recognize ways of subsuming (i.e., moving beyond) the IQ test score as a universal mental yardstick. While the founders of Head Start would distance themselves from that assumption (i.e., by rejecting the so-called IQ trap of empirical assessment), the wider discipline of general psychology (and the testing subdiscipline) would take considerably longer in doing so.
Project Head Start: Rationale, scope, and assessment (1965-1970)
It
was within the political context of the initial War on Poverty budgetary surpluses
that Project Head Start (a program to prepare poor children for first grade by
helping them overcome any fears they might have of school) would be proposed and
immediately nationalized. Zigler & Muenchow's Head Start: The inside story of
Head Start owes its very existence to the disappointing early record of CAP, which focused primarily on efforts to organize and employ poor adults (Zigler & Valentine, 1979). Congress had allocated $300 million for the first year of CAP, but by midyear it was clear that only half the allocation would be spent by the end of fiscal year 1966. When it was ascertained that nearly half of the nation's 30 million poor were children, and most were under age 12, Sargent Shriver (OEO director), drew on his prior social action experience to appoint Dr. Robert Cooke (former Kennedy Science Advisor) to chair an interdisciplinary Head Start Planning Committee.
The
comprehensive scope of Head Start was determined by the committee's very composition.
Only two of the members were early childhood educators. The rest was comprised
of four physicians, a professor of nursing, an associate dean of social work,
a nun who was a College President, a Dean of a
Far from limiting Head Start to an educational program, the resulting program was comprehensive in that it contained both physical health and parental involvement aspects. The health aspect included provision of two nutritional meals a day, immunizations, and basic dental care to Head Start children. The parental involvement aspect (including encouraging parents to volunteer and obtain formal training in child development) became a central hallmark of Head Start. This two-generational aspect was initially based on the realization that no one or two year program was likely to make lasting improvements in child development unless it helps parents become the agents of change. The principle of maximum feasible participation was enshrined in program training manuals after 1969 and distinguishes Head Start from other Great Society job-training and early intervention programs (Harmon & Hanley, 1979).
The educational aspect of Head Start was designed to help kids obtain learning skills and social competencies useful for initial elementary school success. Education therefore was taken, from the very beginning, in its broadest sense. That is, "to include the upbringing of children, and not in the narrow sense of academic instruction" (Zigler & Muenchow, 1992, p.x). This educational mandate of Head Start would be accomplished by way of: (1) ensuring successful early learning experiences; (2) providing an atmosphere of expectancy of success; and (3) encouraging parental involvement in the process. More specifically, on the individual level, the major objective of the program was to increase the range of the child's life experience on both the social (i.e., contact comfort) and societal (i.e., verbal and cognitive skills) levels (see fig 53).

Figure 53 A child benefits from Project Head Start. Shy and withdrawn on his first day, Pancho Mansera soon participates in collective activities which increase his range of social-societal experience (photo from Mckeachie, 1966; after Life Magazine, 1965). Kay Mills' book Something Better for My Children (1998) provides a revealing follow-up on Frank "Pancho" Mansera (who is now an industrial machinist living in California with his wife and three sons).
The
broad definitions and comprehensive scope of Head Start was distinctly similar
to those used in former inclusive research programs (including the Iowa Child
Growth Study, the
Similarly, then, it is in the realm of motivation (i.e., family participation and the internalization of a healthy educational ideology), and not in the realm of statistical abstraction (i.e., performance on standardized tests), that one finds the relevant assessment criteria and ingredients for the actual success (and longevity) of the Head Start program. Indeed, figure 53, is intended to point out the practical difference between the narrow academic mental testing tradition (which concentrates on a purely quantitative comparison of test performance); and the alternative, applied tradition that is concerned more with facilitating a healthy pattern of educational readiness. One tradition is alienating and exclusionary, the other is (at least potentially) empowering. But these historical insights (especially the importance of motivational assessment criteria) were not recognized by initial empirical assessments of Head Start programs, and proponents of compensatory education were quickly put on the defensive.
Initial Assessment
The rapid expansion of Head Start had a price, namely the sacrifice of consistent program quality (Payne, et al. 1973). Initially designed as an eight week half-day summer program for children aged three and four years old, the program was extended the following year to a full-year program. From 1965-1968 the quality of programs varied widely depending on location and formal quality of service controls were only gradually brought into place. One would expect that initial empirical assessments of Head Start (given the evolving nature of program development), would have taken great care in both the study design and conclusions drawn from such research. While such care was evident in the first small-scale case study published (from within the Head Start camp), it was decidedly not the case for the initial large-scale government funded study conducted (the Westinghouse Report).
A
small case study (Wolff & Stein, 1966) of
Meanwhile,
reflecting the wider governmental emphasis on scientific accountability in all
government departments, an ill-fated attempt at national Head Start evaluation
was soon outsourced to the Westinghouse Learning Corporation in conjunction with
Performance on standardized Psycholinguistic and school readiness tests by 1,980 former Head Start kids (70 percent of whom had attended the initial summer programs) were compared to 1,983 other children (now in grades 1-3). The instruments used to measure cognitive effects included: the Illinois Test of Psycholinguistic Abilities; the Metropolitan Readiness Test; and the Stanford Achievement Test. Westinghouse also developed three ad hoc (and unstandardized) attitudinal measures. The report did not find any positive effect of the summer initiatives but did find some for the full-year programs. These Head Start children, for instance, did better on the Metropolitan Readiness Test (a test used to assess readiness for grade one) then the control group and their parents were nearly unanimous in voicing strong support for the program. No significant differences were found between groups, however, for the other measures used.
Partisan Republican views against funding the ongoing Johnson era Great Society' (antipoverty) initiatives was clearly an undercurrent of the design and the conclusions of the Westinghouse report (Hellmuth, 1970). Zigler and other Head Start proponents took issue with the Westinghouse conclusions and so did the main statistician involved in the research (who resigned and refused personal payment for the job in protest). In particular, given that the strongest positive findings turned up for the full-year program group, Zigler was exceedingly surprised when the executive summary of the Westinghouse/Ohio Report concluded that: "Head Start ....has not provided widespread cognitive and affective gains" (Cicirelli, 1969).
It is exceedingly important to note here that, despite the fact that the initial evaluations of Head Start quickly fell into the "IQ trap" assessment (by utilizing standardized tests as a convenient empirical yardstick), the primary emphasis of the program itself was never to raise the scores of societally disadvantaged children on such tests. Rather, the founding aims of Head Start were much broader. That is, even in the so-called "naive" era in which Binetesque mental orthopedics was making a resurgence, the central planners of Head Start managed to avoid such naive environmentalism per ce. As Zigler would later put it:
"I consider it a real victory that there is no mention in the Planning Committee's recommendations of raising IQs. One of the...objectives does specify 'improving the child's mental processes and skills with particular attention to conceptual and verbal skills.' But this language pales by comparison to the fervor of Hunt, Bloom, and other apostles of [naive environmentalism]" (Zigler & Muenchow, 1992, p. 20).
The main problem with evaluation in the early years of Head Start was that the researchers did not know what to measure:
"Public health researchers might have assessed the number of measles cases prevented, or the reduction in hearing or speech problems. Sociologist might have looked at the number of low-income parents who obtained jobs through Head Start. But the only people evaluating Head Start were psychologists, and, for a time, that greatly limited the focus of research" (Zigler & Muenchow, p. 51).
Ironically, since the Westinghouse Report on Head Start was the biggest (and most readily accessible) study, it was long assumed to be the best source. The initial findings of fade-out were then enshrined and generalized in general psychology textbooks as evidence of the so-called failure of compensatory educational programs.
Subsequent assessment
Vindication of Head start as a success would only come later with the Consortium of Longitudinal Studies (1976-1978), a broad-minded (pre-program/ post-program design) which uncovered so-called sleeper effects. The Consortium study was launched in 1976, when 12 investigators collaborated by pooling their independently gathered data and designing a common follow-up protocol.
The follow-up study found that former Head Start kids had significantly fewer placements into special education classes and fewer grade retentions as compared to a control group of other children from the same schools (Palmer, & Anderson, 1979; CLS, 1983). [164] But both the testing tradition and psychologists in general have been slow to recognize the profound implications of such research. These implications are as follows: (1) that a larger societal yardstick must be used to assess the success of compensatory educational programs; and (2) that the maintenance of success (and motivation for success) should be a major part of the mission of the public school system itself.
In historical hindsight, it was in the provision of the initial two-generation structure for the child's immediate school readiness that the mission of Head Start can be said to have been accomplished (Takanishi, & DeLeon, 1994). The wider historical truth of the matter is that the very flaws of traditional interactionism (including the view that IQ scores were a universal mental yardstick; and its underlying rectangular metaphor of human intellect), were only exposed when social scientists (external to the Head Start program itself) attempted to measure the success of Head Start with traditional empirical tools of mental growth. In the shortrun, however, from 1969-1980, liberal interactionists and the professional organizations to which they belonged (such as APA, and SPSSI) were faced with a resurgence of biogenic hypotheses which they were ill-prepared to handle.
Organizational Maneuvers, Disciplinary Adjustments, and Lawler's Solution
During the early 1970s, in both the areas of Head Start and racial comparisons of scores, the fundamental contradiction between existing testing score differences and the ideology of American democracy itself was not well handled by the general psychological community nor by social action groups such as SSPSI. The largely political, face-saving, response (rather than substantive counter-arguments) that were forthcoming during the so-called Jensen controversy are a prime example of this fact. A second indication is that while references to expectancy effects and cultural bias in testing began to be included in chapters on human intellect, they were presented as mere alternative views along side of clearly biogenic accounts.
Recognizing the profound vulnerability of these organizational maneuvers and disciplinary adjustments is key to understanding: (1) why the general psychological biogenic resurgence (of the 1970s and 1980s) was not stopped dead in its tracks; and (2) why an important distinction between inheritance and heritability (made explicit by James Lawler,1978), remained completely unrecognized by the general psychological community.
Organizational Maneuvers (Jensen versus SSPSI and APA)
In February 1969, the Harvard Educational Review published an article "How much can we boost IQ and Scholastic Achievement?" by University of California education professor Arthur Jensen. Coming on the heals of both the government funded Coleman Report -which downplayed the issue of the influence of school quality on test scores (see Coleman & Associates, 1966; Colman, 1972) and the Westinghouse Report on Head Start (mentioned above), Jensen's article signaled the end of naive environmentalism.
Most of the 124-page article was a discussion of the supposed nature, distribution, and inheritability of intelligence, but the first paragraph proclaimed that compensatory education "has been tried and it apparently has failed" (p.1). Jensen suggested that the failure of compensatory education programs (such as Head Start) to boost long-range scholastic achievement test performance might be traced to the heritable nature of intelligence. He placed the heritablity of intelligence at about 80 percent (meaning that 80% of the individual differences in IQ test performance could be traced to genetic differences while 20% of such differences are due to differences in environment).
The highly political and public reaction to Jensen's article on college campuses and in the popular press marked the beginning of the so-called modern IQ controversy. On this very public front, SPSSI released a five page statement to all the major news services outlining their disagreement with all of the major conclusions in Jensen's article (SPSSI, 1969). [165] SPSSI argued that such tests were culturally biased and serving to stigmatize and restrict the opportunities of minority youth. Further, they argued that biogenic arguments based on such tests were morally wrong. But it should be recognized here that SPSSI's de facto arguments on race differences in test performances had changed little from the atmosphere of denial regarding its own fundamental assumptions described a few years earlier by another formerly high profile biogenic proponent (Garrett, 1962). In other words, (rather than merely rationalizing away test results) SPSSI would have to find a way to make reference to something outside the purview of test data itself in order to surmount the nature-nurture issue. After all, as will be describe below, this is what Jensen had done in defense of his so-called biogenic hypothesis. But such a transformative argument (or rather solution to the biogenic account) was not forthcoming at the time.
As for the APA establishment, they elected Kenneth B. Clark (the first African American to hold the position) as APA head in 1970. Clark had been involved in the race and psychology issue for many years. His early research (Clark & Clark, 1947) on the psychologically harmful effects of segregation was utilized by Clark to influence the U.S. Supreme Court in its 1954 decision Brown v. Board of Education at which he testified. [166] Similarly, in Dark Ghetto: Dilemmas of social power (1965) he had pointed out the sociological circumstances of de facto segregation continued to have harmful effects on the nation's young (see also Kozol, 1967). But both Clark and the APA were missing any explicit methodological answer to the biogenic resurgence other than it was morally wrong or ethically ill-advised (i.e., bad for society in general and for black folk in particular) to believe in such views. Something other than face-saving maneuvers and appeals to democratic ideology would have to be mobilized if the pervasive force of scientific racism was to be excised from psychological discourse. [167]
Despite their obvious biogenic biases, Jensen's claims found their way directly into psychological textbooks. In Dember & Jenkins (1970), for instance, students were prepared to address such race differences data by the following apologetic excerpt: "We can save ourselves some difficulty later if we agree now that psychological variation (as long as it is nonpathological) is not a criterion for political judgments of equality or inequality" (p. 537). Despite such disclaimers and qualifications, the fact of the matter is that the inclusion (and therefore tacit acceptance) of such data in textbooks was highly political. With respect to psychological textbooks, then, the initial organizational maneuvers and attempts at ideological maintenance made by SPSSI and the APA had clearly failed.
The subsequent 1970s psychological literature was peppered with an assortment of popular books dealing with the nature-nurture aspect of past testing data. These books were split into two opposing camps: test supporters (e.g., Eysenck, 1971; Herrnstein, 1973; Vernon, 1979) and test deniers (e.g., Guthrie, 1976; Houts, 1977; Blum, 1978). Kamin's The Science and Politics of IQ (1974), in particular, argued convincingly that much of the data used by the hereditarian camp was obsolete, inaccurate, or simply confabulated. But this older biogenic data was only gradually excised from psychological textbooks and the newer biogenic data (e.g., Jensen, 1970, 1971, 1973a. 1973b, 1980) began to be presented as one of many alternative ways of dealing with the ongoing IQ controversy.
Disciplinary Adjustments (Expectancy effects, Cultural bias)
As outlined in the opening paragraphs of this chapter, the standard textbooks of differential psychology (up to 1969) had already made significant steps toward casting off their former belief in any universal mental yardstick (including IQ tests). Both the interactionist standpoint and the use of longitudinal studies were advocated. This subdisciplinary adjustment, however, provided little in the way of addressing the wider realities and ideological issues of American democracy under debate throughout 1960s and 1970s decades. Similarly, it can be argued that the minor adjustments to general psychological textbook accounts of human intellect (between 1970-1980), despite their new sections on expectancy effects, cultural bias, and the Barnum effect, also fell short of addressing the wider fundamentally societal issues of the era. Rather then acknowledging the fundamentally societal origin of these aspects and effects of the testing situation, they were typically explained away in terms of state of the art arguments including the lack of empirical rigor of current tests, poor test design, or sloppy interpretation of past test results.
To address the issue of expectancy effects in mental assessments, Rosenthal & Jacobson's Pygmalion in the Classroom (1968) had presented a case study in which teachers were given a list of several children who were ostensibly predicted to show great gains in cognitive development as indicated by a pretest. In fact, the names were selected at random from the class list. In an IQ test administered at the end of the school year, these children were found to have made significantly larger gains than their classmates. Although the study and its typically naive environmentalist interpretation came under immediate methodological attack (see R. Thorndike, 1968; Elashoff & Snow, 1971) it can still be viewed as evidence of teacher expectancy on classroom performance and subsequent test score performance (Rosenthal, 1973). [168]
In an attempt to address the issue of cultural fairness, tests intentionally developed to reflect a Black culture bias (Dove, 1968; Williams, 1972; Boone & Adesso, 1974; ) were now included in textbook chapters. Robert Williams, in particular, designed the Black Intelligence Test of Cultural Homogeneity (BITCH). From the textbook portrayals it is clear that Williams succeeded in showing that an extremely culturally biased IQ test could intentionally be developed (i.e., one that reversed the traditional score pattern between Black and White students of St. Louis). But the deeper issues of what to do about standardized testing and the reasons for the race performance differences on other acheivement tests remained up to the reader to decide (see Kimble et al 1980 p. 237). As such the BITCH test appears to have been portrayed as somewhat of a joke (i.e., as an ill-conceived form of demonstrative protest with little bearing on testing as a whole).
But Williams (1972) did address these deeper issues. Standardized tests, he suggests are not simply measurements of academic achievement they also function as educational gatekeepers. The system which produced the damage to black youth must therefore be closely examined and modified. Later, the Association of Black Psychologists in a 1975 report published in American Psychologist (January, p. 88) followed up on this theme by charging that standardized testing historically has been a quasi-scientific tool in the perpetuation of racism. They called for a federal truth-in-testing law which would require disclosure about the impact of tests on minorities (see also Guthrie, 1976). This information was entirely absent from contemporary textbook accounts.
Only later would it be understood that the conservative content of textbook chapters on intelligence at least partially sprung from the fact that they were published by those with a direct stake in the testing industry itself including: Harcourt Brace, Houghton Mifflin, and McGraw-Hill. That is, the interactionist approaches to ability testing (and the textbooks written from that perspective during the 1960s and 1970s) did not function to explain or even promote the occurrence of progressive societal change, but rather stood as an administrative and disciplinary barrier to such change. Interactionist (genes plus environment) accounts functioning to rationalize and even perpetuate the intellectual inequalities of American society.
Lawler's approach to inheritance vs. heritability
James Lawler's I.Q., Heritability, and Racism (1978) provides the only substantive (i.e., internally coherent and societally veridical) counter-argument against Jensen and against the racist aspects of test production itself that I can find from the period. First of all, by drawing on prior work by Richard Lewontin, Lawler criticized Jensen (and others) for intentionally blurring the distinction between "heredity" and "heritability." [169] But for Lawler, recognizing the historical fact of heritability of test performance (i.e., the passing down of societally provided educational privilege) was very different from perpetuating innatist or even interactionist accounts of human intellectual differences. His particular approach to the distinction between heritability and inheritance was thus aimed at exposing the widespread false disciplinary (heredity versus environment) quandary encountered when considering ongoing status quo race and class differences in test performance.
While the contemporary focus of popular media was then on the race issue, Lawler points out that Jensen (1969, 1973b) and Herrnstein (1973) both argue for the biologically determined inferiority of particular races and classes. According to Jensen (1973b), studies had shown that Blacks on the average score 15 IQ points lower than Whites, while the difference between socioeconomic classes range from 15 to 30 points. Similarly, Richard Herrnstein's I.Q. in the Meritocracy (1973), stressed class differences and interpreted them along innatist lines.
Lawler was very much aware of the cumulative disciplinary consensus (in both innatist and interactionist camps) at the time that average performance differences (between races and classes) truly did exist and he concurs with this analysis. This was the common empirical ground upon which the battle over nature-nurture was then being fought. The expression of these average differences in performance in Lawler's case were thus in no way at variance with any number of statements in other standard textbooks up to that time or afterward (cf. the Mensh & Mensh, 1991 review of Lawler). The main issue under consideration by Lawler, however, was how psychologists and educators were to best understand, describe, and draw conclusions from those status quo differences in performance.
Lawler's approach is historically important because (in contradistinction to both the innatist and interactionist camps), he brought to bare not only an understanding of population genetics (i.e. standard procedures of heritability analysis used in other fields of study) but also a useful set of dialectical materialist (i.e., socio-historical) analytical tools to the issues at hand. Lawler makes it clear that by mobilizing the concepts of population genetics, Jensen was intentionally pulling the proverbial wool over the eyes of relatively lowbrow general psychologists and educators in an effort to provide vicarious support his biogenic biases. As Lawler puts it, Jensen performs a "sleight-of-hand" (p. 136) when passing from a standard discussions of Black vs. White test score differences to the relatively technical realm of population genetics (see also Dobzhansky, 1973; Lewontin, 1976; McGuire & Hirsch, 1977 for similar arguments).
That is, in addition to reporting racial differences in IQ test performance, Jensen appealed to the methods of population genetics to indicate that IQ performance is 80% heritable. This assertion gives the impression to the lay reader that a large part of our intelligence is inherited and owes relatively little to the environmental circumstances in which we have grown up. In population genetics, however, the heritability of a trait does not mean how much of some trait (the phenotype) is due to the genes (the genotype) as opposed to the environment. Nor does it refer to something that is fixed. In fact, the heritability estimate of a trait (i.e., the passing down of a given phenotype) can change drastically according to changes in environmental circumstances.
Jensen was "perfectly aware of the technical usage of ...heritability" (p. 135). The main reasons for his disingenuous portrayal of this term (and the motive behind it) were: (1) the intent to "render plausible" the hypothesis that observed differences between IQ scores for Blacks and Whites is to be sought in genetic differences; and (2) to suggest that ameliorative educational (or equal opportunity initiatives) are a waste of time.
Like Jensen, Lawler appeals to something outside the operational definition of IQ (or ability) tests themselves in order to tackle (and in this case surmount the false dichotomy of) the nature versus nurture debate. Lawler's external criterion is the history of American society (including its history of systemic racism and inequality of educational opportunity). Before elaborating on this point, it is important here to point out that subsequent attempts to bring social considerations into test score analysis would be made by interactionist thinkers. But these attempts, I would argue, where mere methodological half-steps. For example, the closest that the interactive approach eventually came to developmental analysis of human intellect is the following formula modified (i.e., expanded) from Lewontin et al. (1984) -where environmental variance is explicitly partitioned into social and societal "factors" (such as family size and SES) which are then compared to so-called genetic variance:
Heritability= genetic variance
genetic variance + environmental variance
This formula was the pinnacle of the 1970s and early 1980s interactionist account of human intellect. Yet it was hardly a major shift from Bloom's footnoted elaboration on the so-called naive environmentalism of the 1960s (mentioned above) in that it makes reference to both "genetic" variance and social environment (see also Anastasi, 1982, 1984; Scarr, Weinberg, & Waldman, 1993; Scarr, 1998 for similar accounts ).
Lawler's
account is more transformational than those of both the innatist and the interactionist
camps. Genes (genetic variance) hardly comes into the account at all except that
the subjects of interest here are all human beings. Educators and psychologists
have wasted much time on this hereditarian byway. The more relevant mechanisms
of description and explanation are those of social-historically available means
of transformation of individuals (schools; subcultural views on education; economic
opportunities, etc.).
His
major point is merely that such heritability of intellectual talent (as indicated
by standardized tests) is a socio-historical product indicative of the status
quo of the American economic and educational system. It is not equivalent to inheritance
of abilities via the genes nor should it be methodologically reduced to the effects
of descriptive empirical indicators such as SES. While the ontological significance
of IQ score variability is clearly correlated with class ranking the reasons for
the past stability of this pattern are to be sought in both the ongoing conditions
of historical inequities and in the effects which these conditions have upon the
lives of the varied cultural subgroups concerned.
My
motive for emphasizing Lawler's account in this thesis is that it demonstrates
that past empirical evidence (including race, class, and male vs. female data)
is only a problem if one does not have a threefold transformative understanding
of intelligence (i.e., from individual, to social, to societal intellect). One
indication of the robustness of the approach is that it is both consistent with
and actually clarifies the meaning of the contemporaneous and subsequent more
reputable adoption studies data.
Most
notable among the contemporaneous studies are those by Scarr & Weinberg (1978)
and Horn et al. (1979), using families containing "natural and adopted"
children. They both found that "children reared by the same mother resemble
her in IQ to the same degree, whether or not they share her genes" (see Lewontin,
et al., 1984, p. 113). For Lewontin et al. (1984), this data indicated that the
predominant factors in the passing down of IQ test performance lies in the wider
social realm of family environments and/or educational opportunities provided
by adoptive parents. According to Lawler's account (as I understand it), however,
the first part of the preceding conclusion is both nonsensical and beside the
point. All the data shows is that the educational opportunities provided by an
adoptive White parent at that juncture in American history varied considerably
for that afforded by Black adoptive or "natural" parents.
Again,
the spitting of theoretical hairs between these two accounts (which seem to be
saying the same thing) is more important than one might think. For Lawler, inheritance
has no place in the analysis of the development of higher mental functions in
human beings and should be relegated to the metaphysical scrap-heap of psychological
science (along the lines of the throwing out of the prime mover in the realm of
physics). Not so with interactionists on either side of the false genes + environment
divide. Later empirical and historical developments would soon drag this fact
into high-profile disciplinary relief and should therefore be mentioned.
On
the one hand, the failure of the earlier noted pattern of heritability of IQ scores
to reappear in subsequent follow-up adoption studies prompted the retractions
and slips back into Jensen-like interpretations characteristic of Scarr &
Weinberg's later work (see Scarr, Weinberg, & Waldman, 1993; Scarr, 1998).
It also created a disciplinary nightmare for the proponents on the environmental
side of dynamic interactionism.
In
contrast, both Lawler's consistent portrayal of test heritability patterns as
products of socio-historical forces, and his arguments against the narrow psychometric
definitions of societal factors are completely applicable to these subsequent
developments. Rough psychometric patterns of test score heritability, characteristic
of an earlier time, should not be expected to continue in perputum and the very
expectation that they would indicates the considerable investment in the genes
vs. environment fallacy (and/or historical naivete) of those still carrying out
such research.
It is indeed a shame that mainstream textbooks have failed to explicitly adopt this valuable socio-historically informed approach to such theoretical distinctions. In the future, perhaps we should demand they do. Indeed, as Lawler points out, the implications of starting in this social-historical realm of inquiry are quite positive:
"If intelligence is not innate, but a social, historical product, if a truly scientific pedagogy located the obstacles to learning in the practical [educational] environments of the children, both in and out of school,... and if it is recognized that the talents of people are systematically wasted and destroyed, and if a deeper cultivation of a scientific culture among the entire population is possible, then what follows is not resignation, passivity, fatalism and despair, but recognition of real possibilities, and active approach to education, outrage at the injustices committed, and determination to fight for educational rights" (Lawler, 1978, p. 5).
Further, this socio-historical starting point was not intended by Lawler as an end in itself but rather as a basis upon which further progressive psychological discourse could be built. Lawler's, closing argument (in his chapter on Real Science and Real Freedom), for instance, aptly states what was needed: An approach which promotes "further advances in the democratization of education," responding to the real needs of development in modern society, and "which begins to locate the obstacles to this development not in the people as a whole, but in a socioeconomic system that subordinates the needs of the vast majority to the private interests of the few" (p. 181; emphasis added).
Although, at the time, this function of locating such obstacles (and of imposing substantial reforms to the status quo), was not being performed by the professional maneuvers or by the testing subdisciplinary adjustments described above, it was (as described below) being performed by both the law courts and by ongoing investigations into the corporate structure of the Educational Testing Service (e.g., the Nader Report, 1980).
Ability Testing Under Attack (1970-1981): Testing Litigation and ETS evasions.
It is important to recognize that the professional maneuvers, attempts at ideological maintenance, and adjustments to textbook accounts (described in section two) did not take place in a socio-historical vacuum. They coexisted with both ongoing legal cases and important expositions of the corporate structure of the testing industry. It was from these outside sources, and not from within the testing subdiscipline nor from within the organizational structure of general psychology, that progressive changes occurred during the 1970s.
This section describes the testing litigation which shifted the burden of proof (in both educational and vocational areas) from the tested to the test givers. It also describes how the long-lived vicarious respectability of the ETS was eventually tarnished by way of the Nader report (1980) which exposed the secretive and rather undemocratic underbelly of this so-called nonprofit testing organization.
In brief, the fundamental issue which the press and the courts were now attempting to grapple with was: how to best modernize the very ideology of American democracy (which from the very start had married a call for liberty to a postulate of equality). The modern expressions of this ongoing (i.e., historically situated and shifting) objective contradiction of democracy clearly required significant reform of public policy in order to ensure: (1) equality of (and access to) higher education; and (2) fairness in vocational assessment.
Both social Darwinism and the mid-century testing industry had failed to deliver on their initial promises in those regards. Hence, between 1964-1981, the infrastructure of differential psychology (which had grown as a result of addressing the conservative administrative desire for maximum industrial output and for efficient academic assessment), came into direct logical contradiction with a new political consensus (i.e., that the actual opportunities of modern American life should better reflect the traditional democratic ideology of human equipotentiality).
Testing Litigation in the 1970s
From 1964 through 1978, the federal government began targeting its assistance toward students whose education had been a low priority in State and local school system (poor, minority, handicapped, and female students). Legal cases regarding both discriminatory aspects of testing in school tracking systems and in vocational arena, however, were also an important aspect of the era's testing landscape. The result was a short-lived, yet substantial, reform in test use practices in schools, employment, and admission to higher education.
Tracking decisions and the Burden of Proof
Late 1960s and early 1970s test litigation and legislation seems to have decreased the overall use of standardized tests for the purpose of student tracking during the late 1970s. In a 1964 nationwide survey conducted by Akron, Ohio, public school administrators, 100 percent of large city and county test directors polled reported using group ability tests in grades 4-6, and in grades 7-9. A 1977 follow-up found that the frequency of test use had declined dramatically, to 23.4 percent in grades 4-6 and 35.1 percent in junior high school (Dimengo, 1978).
The movement away from tracking, and from the use of ability tests in making tracking decisions, was given a substantial boost by a 1967 Distric Court decision: Hobson v. Hansen ( the first in a series of cases involving testing to have a major impact). In Hobson, the ability grouping system then in existence in Washington, D.C., public schools was challenged as being racially discriminatory as defined in Title VI of the Civil Rights Act. The main evidence was the disproportional enrollment of Black children in lower ability groups. The fact that Black children scored lower on such tests was judged tantamount to racial bias, and the Washington DC tracking system was struck down (Snyderman & Rothman, 1988).
The onus of the Hobson decision was felt in Larry P. v. Wilson Riles. In November 1971, the parents of seven Black children brought suit against the State of California, claiming their children had been incorrectly placed in classes for the educable mentally retarded (EMR) on the basis of culturally biased tests (Hilliard,1983). The plaintiffs, with the assistance of the Bay Area Association of Black Psychologists, the Urban League, and the NAACP Legal Defense Fund, charged that test scores from (individually administered) intelligence tests were the primary determinant of EMR placements. The resulting disproportionate EMR enrollment was accepted as prima facie evidence of discrimination (thus shifting the burden of proof to the defendants to show a rational connection between test scores and their alleged use). A preliminary injunction was granted in 1972 barring future placement of black children into EMR classes on the basis of IQ test scores.
The ugly fact of the matter was that, at this time, Black urban children were sixteen times more likely than White urban children to be assessed as retarded on the basis of the commonly used Wechsler scales. Jane Mercer (1973) as a representative of the testing industry responded to this fact by suggesting that a "calibrated system" of statistically adjusting minority IQ scores upward (called SOMPA -System of Multicultural Pluralistic Assessment) be adopted. Standardized mental assessment procedures, that is, should be broadened to include both a behavioral sample (including participation in family dynamics) and a consideration of other relevant information (such as, neighborhood setting and school quality) when used to estimate minority student IQs (see Mercer & Lewis, 1978). In 1974, despite this proposed subdisciplinary adjustment, the standing court injunction was broadened to include the elimination of IQ testing of all Black children in California, and a year later the State extended the moratorium for placement of all students into EMR classes.
A subsequent seven months long Appeal round of herrings on the Larry P case then began in October 1977, and twenty-six expert witnesses were called in an attempt to establish the validity or invalidity of individually administered IQ tests for EMR placement. The final court decision, in 1979, was essentially the same as in the preliminary hearing. It found cultural test bias to be the most reasonable explanation for disproportional Blacks EMR student placements, and barred the State from using IQ tests for Black placements without approval of the court.
Ironically, while Judge Peckham was reaching his ruling on the Larry P. case, California was already in the process of revising its system of special education to accord with the federal government's Education for all Handicapped Children Act of 1975. Under its Master Plan for Special Education, California abolished the EMR classification of students and was to phase out the former practice of educating handicapped students separately from their non-handicapped classmates.
Vocational Tests and the Burden of Proof
Charges of racial discrimination in employment practices through use of standardized tests were the most common and most successful form of test challenge in that decade. Of 70 Title VII cases decided by federal courts between 1971 and 1976, 80 percent were won by the plaintiffs (Dimengo, 1978 in Snyderman & Rothman, 1988).
An important legal precedent in vocational test challenge cases, where adverse impact is taken as prima facie evidence of discrimination, was established in a March, 1971 Supreme Court ruling on the case of Griggs v. Duke Power Co. In addition to its former policy of requiring a high school education (1955) the Company added a further requirement for new employees on July 2, 1965 (the date on which Title VII of the Civil Rights Act became effective). To qualify for placement in any but the Labor Department, it became necessary to register satisfactory scores on two professionally prepared aptitude tests (as well as to have a high school education). Incumbent employees who lacked a high school education, were permitted to qualify for transfer from Labor or Coal Handling departments by passing two tests - the Wonderlic Personnel Test, which purports to measure general intelligence, and the Bennett Mechanical Comprehension Test. Neither test however was intended to measure the ability to learn to perform a particular job or category of jobs. The requisite scores used for both initial hiring and transfer approximated the national median for high school graduates and 58% of the White employees passed such tests, as compared with only 6% of the Black employees (Griggs v. Duke Power Co. Ruling, 1971).
In the final resolution of the Griggs case, the Supreme court placed the burden of proof upon the employer to show that the tests in question is a reasonable measures of job performance. It was now deemed unconstitutional to require a high school education or to require passing of a standardized general intelligence test as a condition of employment in or transfer to jobs when: (1) neither standard is shown to be significantly related to successful job performance; (2) both requirements operate to disqualify "Negroes" at a substantially higher rate than White applicants; or (3) the jobs in question formerly had been filled only by White employees as part of a long-standing practice of giving preference to Whites.
Subsequent cases further established the practice of showing great deference to the Equal Education Opportunity Commission (EEOC) Guidelines on Employment Testing Procedures (1978). The EEOC was charged with enforcing Title VII of the 1964 Civil Rights Act, dealing with unfair labor practices. This dealt a virtual death blow to the use of aptitude tests in private employment settings. The EEOC Guidelines rely heavily on the APA Standards of Educational and Psychological Tests (1955, 1966, 1974, 1985) which made recommendations for validation criteria for test developers with resources to conduct validation studies involving hundreds of subjects. Individual employers, on the other hand, could rarely afford to conduct such studies, and so had previously relied on the often sketchy validation claims supplied by the test producers (Pearn, 1978). The courts were, in general, unwilling to accept supply-side validity claims in cases where adverse impact was demonstrable.
Snyderman & Rothman (1988) mention a resulting climate of fear being produced in which the elimination of employment testing by many firms resulted. A 1976 survey of 200 companies found that 42 percent were using employment tests, compared to 90 percent doing so in prior 1963 survey (Miner & Miner, 1978). Both this study and that of Pearn (1978) confirmed the test decline projection of a larger (Prentice-Hall, 1975) survey of 2000 American Society for Personnel Administration member companies. The tide of vocational assessment policy in the private sector seemed to be turning toward other selection procedures (e.g., interviews, prior experience, educational attainment, and biodata) which the courts would be more willing to accept (see also Tenopyr, 1981; Hale, 1982).
Employment testing in the public sector, far more common than in private industry, was also effected by litigation. A major setback to the Civil Service tradition of generalized testing came with a 1981 decision involving the federal government's Professional and Administrative Career Examination (PACE) given to over 150,000 applicants each year for entry level positions. Douglas v. Hampton, a suit originally brought against the U.S. Civil Service Commission in 1972, initially alleged discrimination against Black applicants through the use of the Federal Service Entrance Examination (FSEE), a generalized test of verbal and quantitative reasoning used form employment in over 200 federal jobs (Savas & Ginsburg, 1978). In 1975, while the case was on appeal, the Civil Service Commission replace the FSEE with PACE, a carefully constructed and researched exam measuring five types of ability (purportedly correlated with performance in 118 jobs). The five subsets could be weighted differently depending on the job in question. Despite its apparent predictive validity, a 1979 Title VII challenge to PACE led to the 1981 consent decree that called for the elimination of the PACE over three years. The federal government then moved toward separate, highly job-related exams for each job category (Snyderman & Rothman, 1988).
The immediate response of the vocational testers to the new context of judicial confines is well exemplified in various October 1981 American Psychologist articles. Mary Tenopyr (of AT&T) complained that while vocational testing seemed to be on the "wane," the "government-mandated" search for alternatives was equally if not more problematic and further that the existing test industry "fairness models" for testing different groups (by Cronbach and others) posed more problems than the traditional universal cut-off standards. "[N]o employer is officially going to place different numerical values on the selection of persons of different races or sexes" (p. 1122). While these two complaints are understandable within the context of the ongoing subdisciplinary adjustments, the most problematic statement in the article -that "Tests do not discriminate against various groups; people do" (p. 1121), was a completely unconvincing denial of past voctational testing history (see Hartigan & Wigdor, 1989).
Similarly, Schmidt & Hunter's (1981) article, explicitly starts with the standard corporate line: that vocational test selection equals savings in dollars for the businesses using them (p. 1128). That is, it starts with a dogmatic statement of the historical raison d'être of vocational testing itself (see Baritz, 1960). The related point that average vocational ability and cognitive skill differences between groups are "real" and are "directly reflected in job performance" (p. 1131) is then led up to by way of appeal to "state-of-the-art meta-analytic procedures" for carrying out "across study" assessments of vocational test reliability and predictive validity (pp. 1128-29). Notable in their absence, however, are any details about the actual tests being referred to or any mention of the important r-squared (variance of predictability accounted for) values of these lucrative vocational tests. This sort of evasion eventually led Michael Sokal (1984) to demand that insider testing histories be more clear about which tests or apparatus are being discussed.
Most importantly, however, Schmidt & Hunter, as unabashed servants of power dismissed (by way of exclusion from coverage) the main historical point of the 1970s vocational testing litigation: That equality of access to educational or workplace training, and to vocational opportunity itself was a just (though practically challenging) goal for a democratic society to take on. Instead, they argue that since the measured differences are real, the tests themselves "do not cause 'adverse impact' against minorities" (p. 1131). Even the potentially viable middle ground argument seems to have escaped the immediate purview of their highly reactionary account (i.e., that standardized vocational tests might be most useful for prediction of future job performance after equal access to training or professional upgrading was made available to the applicants/employees concerned). But, of course, such a fair-minded and voluntary withdrawal to the middle would inevitably cut into the bottom line of vocational testers (though not necessarily industrial psychologists).
Fall from grace for the ETS
In 1980, Columbia University student Allan Nairn and his associates, working under the auspices of consumer advocate Ralph Nader, published The Reign of ETS. In this "Nader Report" criticisms traditionally reserved for intelligence and vocational tests were directed at tests used in higher education admissions (including the SAT, LSAT, MCAT, and GRE). In order to gather the information contained in the report, Nairn & Associates had to overcome both a long heritage of ETS closed-door business practices and a considerable institutional reluctance to grant interviews. What they came up with was a shocking expose of earnings, corporate structure, test production procedures, assumptions, and public image campaign of the so-called nonprofit Educational Testing Service (founded 1947).
The founding and early years of ETS have been covered and its first great expansion during the 1950s into military deferment, higher educational testing (using SAT and GRE) and the Cold War "search for talent" was said to have garnered it a vicarious respectability. This respectability would be considerably tarnished by the Nader Report and the issue of admissions tests would become a matter of ongoing public concern (Linn, 1982a&b; Linn, 1986).
Non-profit status and test products of ETS
After an introductory account of past testing traditions, the argumentative weight of the Nairn & Associates report begins to sink in from about page 40 onward. The ETS has non-profit status and is exempt from federal taxes by the same section of the IRS code which exempts garden clubs, civic groups, cooperative nursery schools and burial societies. Despite its worldwide sales to millions of customers and despite its estimated $94 million annual income (1972), the ETS is considered nonprofit because it pays no money to stockholders and plows revenues back into the company. Yet ETS sales, which doubled every five years from 1948-1970s generated a sizable pool of retained earnings (pp. 40-41).
Chapters VII and VIII on ETS business practices and corporate organization, in particular, reveal how this non-profit status allowed ETS to both project an image of "benevolent authority" while avoiding scrutiny by the Federal Trade Commission. When Allen Nairn contacted the New York Board of Regents (responsible for monitoring non-profit organizations in the State), for instance, the Board did not even know what the ETS was. This non-transparency allowed ETS to use "tactical defenses, secrecy, manipulation of the facts and even deceptions" whenever their policies, practices or methods were questioned (pp. 280-92).
A near monopoly status in certain highly profitable areas of testing (such as college and graduate school entrance) and its ownership of the tests used by these so-called "client organizations" (such as the Graduate Record Examination Board) has allowed ETS to forge long-standing tying agreements with its client organizations (i.e., agreements which restrict their business options). This corporate set-up both ensures ETS profit (even if client groups show a financial loss) and also serves to minimize competition from other non-profit organizations (such as the American College Testing program). Once a client group has "chosen" ETS to administer a test program for their level of education, the only option for a competitor (such as ACT) is to approach individual institutions (one by one) to also require their tests (p. 329).
By the time of the Nader Report, the tests products of this omnipresent organization were being used throughout the entire course of American educational life including: Preschool and Elementary assessment (Cooperative Preschool Inventory, Sequential Tests of Educational Progress); High school admission and Graduation equivalency (Secondary School Admission Test, General Educational Development test); College admission and Financial Aid (Junior Scholastic Aptitude Test, Preliminary Scholastic Aptitude Test, National Merit Scholarship Qualifying Test); Graduate school admission (GRE, LSAT); Business school admission (Graduate Management Admissions Test); and Certification to Teach (National Teacher Examinations).
What do these ETS Aptitude tests measure?
By far, the largest ETS income source is its so-called scholastic aptitude tests including the PSAT/NMSQT, SAT, LSAT, GRE, and GMAT (see fig. 54). Along with its non-profit status came a lack of candor with respect to what these tests actually measured. In fact, Nairn describes the shifting ETS portrayals of aptitude tests as a "respectable fraud" (p. 58). The contemporaneous ETS claim that an aptitude test measures the capacity or potential of an individual for a particular kind of behavior is successively challenged in the Nader report by way of both previously unavailable internal (ETS) studies on test predictability, and by way of external studies of test predictability and class bias.

Figure 54 Taking standardized tests (1960s). By the early 1960s, the number of SATs taken each year was roughly equivalent to that of 1/4 of the U.S. 18 year old population. That number had jumped to an equivalent of 33% by 1976-77 (photo from Whittaker, 1976).
According to ETS validity studies carried out between 1964-1974, use of the SAT delivers a predictability of 11.9% of the variance in first year grades. What this means is that for 88% of college applicants (no one knows which ones) their SAT scores has no more predictive power than a roll of the dice (p. 59). Further, according to validity figures which ETS presented in 1977 to the Carnegie Council on Policy Studies in Higher Education, other ETS aptitude tests provided similar or slightly lower percentages of predictability: LSAT=13%; GRE=11%; GMAT=8% of first year grades (pp. 60-62).
These ETS validity studies also indicate that high school grades are about twice as good as SAT scores in predicting first year college grades. Although the SAT is an inferior predictor, it is often argued that using them in combination with prior grades can increase the predictive power of admissions. But Nairn demolishes this argument by presenting a table (compiled by Ford & Campos, 1977, for the College Board) showing that such a combination only increased SAT prediction of first year grades by 3-5% for the years between 1964-1974. This thin margin is the "single rational function from which the ETS aptitude testing empire hangs" (p. 66).
Statistics on test scores and college success, however, can never reveal what might have been accomplished by those who were rejected due to their test scores in the first place. A rare practical experiment designed to address this issue was carried out by Williams College (Massachusetts) between 1965-1975. Over this ten year period, 358 students (roughly 10% of each year's class) who would have otherwise been rejected on the basis of test scores were admitted and their progress was monitored. The identity of these ten percenters was kept secret from both faculty and students. Seventy-one percent of these students graduated compared to the Williams average of 85% and in one graduating class the class president, the president of the college council, and the president of the honor society had all been admitted under the special program (p. 74). [170]
From 1959 onward, the ETS claim had been that aptitude tests ranking candidates by their potential for accomplishment (p. 55). McClelland (1971) in American Psychologist, however, reported no consistent relationship between aptitude scores of college students and their life accomplishments in social leadership, the arts, science, music, writing, and speech and drama. Similarly, Baird (1979) indicated the same lack of relationship for NASA scientists and concluded that biographical information about past accomplishments is the best predictor of future accomplishments.
Further, Marston (1971) found that a comparison of GRE scores to "scholarly output" for University of Southern California PhD in Psychology students (between 1953-66) yielded only a 3% variance accounted for prediction for Clinical students and a negative correlation for nonclinical student's. Given this lack of predictability of life accomplishments, it was indeed time to "reconsider" both the use of GRE scores in admissions and to abandon the false notion that ETS aptitude tests (such as the SAT) predict anything outside the so-called "charmed circle" of first year grades in college (see Nairn, pp. 76-81).
Class in the Guise of Merit
What ETS tests such as SAT and GRE are good at is ranking candidates by their socioeconomic class. In fact, the "single most important aspect" of tests is their ability to rank candidates by income (Nairn, p. 113). Indeed, as indicated previously, the link between test scores and social class were at the very heart of how SAT and GRE test items were originally selected (prior to their purchase and use by ETS).
Nairn narrows down the timing of this shift in claims regarding the meaning of aptitude tests to an ETS test booklet You: Today and Tomorrow (1959). The subsequent claim was that such tests allow students regardless of race, religion or sex to run the same race. But this relatively modern ETS claim that standardized aptitude tests replaced prior idiosyncratic ranking based on class with an impartial ranking based on merit is misleading (p.199). The continued denial of class bias by the ETS and contemporary denial of racism by proponents of psychometrics was a source of considerable frustration for critics and for students as well (see fig 55).

Figure 55 Taking ETS Achievment Tests (1970s). By the late-1970s, legal challenges, an unfavorable Federal Trade Commission investigation into ETS denials over the effectiveness of testing preparation courses, and charges of class bias in tests worked together to produce considerable doubts as to the meaning of what achievement and aptitude tests actually measured (Photo from Evans & Murdoff, 1978). Despite contemporary ETS denials, College Board data itself reveal considerable class bias effects for students taking the 1973-74 SAT. Students with an average SAT score of 750-800 (800 being the highest score), for example, were found to come from families with an average income of $24,124. Students with scores from 700-749 came from families with an average income of $21,980; students who scored slightly lower -from 650-699- came from families with a slightly lower average income -$21,292. This correlation held firm for not only rich versus poor students, but through every bracket of income scale (Nairn 1980, p. 113).
Once again, data gathered through the ETS itself does not support their claim of class neutrality. In a massive College Board statistical report on students taking the 1973-74 SAT, students from families with higher income, tended to attain higher SAT scores. [171] Further, and quite importantly, this pattern holds nearly constant across ethnic and geographical boundaries. In other words, "the lower average scores of minority applicants are primarily a reflection of what is perhaps the single most important characteristic" of the SAT test, "its tendency to rank people by income" (Nairn, p. 113). Importantly, this data seems to vindicate Lawler's (1978) understanding of standardized tests and sheds light on the issue of the economic source of so-called racial differences in standardized test scores.
This theme of ranking by class is taken up again later in the Nader report: In 1978-79, applicants averaging below 350 on the SAT had a mean family income of $18,400 while those averaging 650 or over had a mean of $33,400. According to other figures compiled for the College Board a student from a family earning less than $4,600 (1969-70) had a 10% chance of scoring above 450; in the $7,500 to $10,699 range, the chances had doubled to 21%, and above $16,200, they quadrupled to 40% (p. 203). This amounts to ranking by class "in the guise of merit" (Nairn p. 219). By such misrepresentation, the ETS is not only guilty of false advertising, it also routinely "reduces both the aspirations and opportunities of millions of people" (Nairn, p. 219; see also White, 1982).
Truth in Testing Law (
In
1979, as a result of lobbying by New York Public Interest Research Group (NYPIRG)
and the Nader group, New York Sate passed a truth-in-testing
law requiring all admissions test makers to release the contents and answers of
their tests to the general public within a specified time after administration.
The law was passed over the objections of ETS representatives who argued that
writing new questions to comply with the law would necessitate heavy fee increases
for
Nairn (1980) openly questioned the veracity of this dilatory ETS claim:
"Although the [ETS] has 2,300 full-time employees, few spend their time writing educational tests. In 1949, an estimated ten of ETS' fifty-two professionals actually wrote tests. In 1974, ETS test development professionals known as "Examiners," numbered less than eighty and comprised less than four percent of the ETS staff. According to internal ETS organization charts, by May of 1978, the staff of examiners had shrunk to less than seventy people who were turning out tests to measure the minds of perhaps seven to nine million test-takers a year" (p.142).
Test development activities do not absorb a large portion of candidate fees. According to a 1972 ETS Activity Analysis, they account for less than 10% of the cost of producing an ETS test (Nairn, p. 148) For the SAT, the ETS typically spent an average 25 cents per candidate writing the questions. Total test development costs came to 33 cents per candidate (or 6.5% of all costs involved in each SAT test). For the LSAT, test development was only 4.5% of cost, and for the PSAT only 1.9%. Most of the cost for each test line were attributable to the physical production operations such as administering the tests, registering the candidates and scoring and reporting the results (Nairn, p. 149). The ETS resistance to the Truth-in-testing legislation, therefore, amounts to political grandstanding and institutional damage control.
First, the unreflective rectangular metaphor of human mentality (1945-1965), then the naive environmental approach (1960-1969), and finally the era of equality liberal interactionist account of human mentality (1970-80) had their turn in the disciplinary sunlight. Unfortunately even the liberal interactionist approach to the development of animal and human intelligence was not a sufficient break with late-19th century mental Darwinism. Instead, it was merely the latest version of an underlying additive continuity view of mind dressed up in mathematically technical terms. The perpetuation of this underlying assumption of continuity, more than anything else, has made both the subdiscipline of mental assessment and the discipline of general psychology vulnerable to critics of all sorts.
Only through occasional attempts including: (1) Zigler and others connected with the Head Start movement who openly addressed the motivational and two-generation aspects of intervention programs in order to highlight their success (thereby casting off the IQ Trap of mental assessment); and (2) the testing outsider James Lawler who characterized the heritability of test performance as resulting from a passing down of societal privilege, was the kernel of a solution to the ongoing practical and theoretical contradictions of interactionism presented. But as shown in the next chapter, Zigler's insights into the procedural success of Head Start were not adequately carried over when he was given an opportunity to address the issue of the content of human intellect itself. Similarly, Lawler's alternative approach to test interpretation was not adopted by mainstream psychology (partly because it relied on left-wing ideological assumptions fundamentally different from those of ongoing liberal democratic efforts at solution).
Under the wider 1970s discussion of credibility gaps, and calls for public accountability, the formerly held Cold War era public prestige and disciplinary mystique of mental testing was bound to melt away (Haney, 1981; Mensh & Mensh, 1991). What followed was an era of testing malaise (with regard to the possible reform of long-entrenched ETS administrative traditions of assessment in general) and of political correctness (regarding the origin of race differences in test performance in particular). From 1981, onward, the conclusion of fair-minded reviewers seemed to be that: "standardized testing [is] out of step with the demands of the changed social context in which [it] is being applied" (Gordon & Terrell, 1981, p. 1170). Although some of the signs were already there, what such reviewers didn't know, was that traditional psychometrics would soon be granted both a stay of execution and new areas of expansion as the wider political context of malaise turned toward one of a federally mandated (and right-wing ideologically guided) era of accountability.
[157] In June, 1964, two American
aircraft carriers arrived in the area and after LBJ's election on
[159]Rate of induction in fall 1969 (19,000/month); fall1971 (2,000/month); 1972 (4,100/month).
[160]There are currently three versions of the ASVAB. The first version is Form 18/19, which is the paper-based test commonly given to juniors and seniors in high school. The test is administered annually or semiannually at more than 13,000 high schools and post secondary schools in the
[161] The AFQT score is not derived from all portions of the ASVAB. Indeed, the score is determined from only four areas. The score is computed as follows: [2 x the number correct on World Knowledge] + [2 x the number correct on Paragraph Comprehension] + the number correct on Arithmetic Reasoning + the number correct on Mathematics Knowledge. This formula results in the AFQT "raw score," which is then converted into a percentile score. Several areas of the ASVAB are not used at all to compute the AFQT score. Word Knowledge and Paragraph Comprehension are worth twice as much as Arithmetic Reasoning and Mathematics Knowledge.
[162] Among the direct costs to the U.S. were the lives of 58,000 American personnel and $150 billion in military aid to South Vietnam.
[163] "As society is now constituted, persons of inferior stock tend to intermarry. They often have many children. Furthermore, these children usually are reared in inferior environments and inferior individuals usually result. Is it too much to hope that someday society will encourage superior persons to marry and discourage the reproduction of inferior individuals? Is it too much to hope that someday people will give more serious consideration to the improvement of environment? Will they broaden both the base (heredity) and the altitude (environment) of individual lives so that the resulting human race will be truly superior?" (Engle, 1957, pp. 268-269).
[164] Subsequent controlled follow-up studies (e.g., Hohmann, Banet, & Weikard, 1979; Palmer & Anderson, 1979; Epstein, & Wikart, 1984; Lee, Brooks-Gunn, & Schnur, 1988) indicated clearly that ex-Head Start kids show more competence in school work and general social adjustment measures (i.e., less likely to need remedial classes, exhibit less antisocial behavior, and are more likely to hold after-school jobs). Similar positive effects of family support intervensions were also found (Seitz, Rosenaum, & Apfel, 1985).
[165] A group called Psychologist for Social Action also urged Jensen's expulsion from the APA. Similarly, the 1969 convention of the American Anthropological Association (AAA) passed a resolution condemning Jensen's position on racial differences and encouraging members to fight racism through the use of all available outlets including the national and local media. Later, organizations like the NAACP, and the Association of Black Psychologists called for complete moratorium on standardized tests (see Kamin, 1974; Houts, 1977; Strenio, 1981).
[167] APA membership jumped from 11,069 in 1954 to APA and by 1968 to 23,077 (Hilgard, 1980, pp. 760-767). Importantly, however, the relative preponderance of clinical types to non-clinical had also increased. The long-standing experimental basis of the APA membership was begining to erode and the clinical and ability testing concerns of the profession were becoming much more priminent.
[169] Some definitions are important here: Heredity is defined variously as: (1) The passing of qualities from parent to offspring by processes which occur first in the nuclei of germs cells; and (2) the sum of qualities passed from parent to offspring. Heritablility on the other hand is typically defined as: (1) able to inherit. When considering the heritability of human intellectual qualities, therefore, it is important to note the first and third meanings of inherit which follow: (1) to receive by legacy; (2) to receive by heredity; (3) to come into an inheritance. Only the second definition of inherit is necessarily read as a biogenic affair. In contradistinction, the first and third are more aptly understood in this case as socio-historical in nature (i.e., not necessarily having anything to do with genetic variance or race, etc., but certainly having everything to do with culture, economic class, family relations, and the history of access to education).
[171] Students with an average SAT score of 750-800 (800 being the highest score), for example, were found to come from families with an average income of $24,124. Students with scores from 700-749 came from families with an average income of $21,980; students who scored slightly lower -from 650-699- came from families with a slightly lower average income -$21,292. This correlation held firm for not only rich versus poor students, but through every bracket of income scale (p. 113).